
Sàng Eratos hay sàng số nguyên tố là giải thuật tìm mọi số nguyên tố trên đoạn $[1;n]$ với độ phức tạp $O(n \log \log n)$.
Ý tưởng giải thuật:
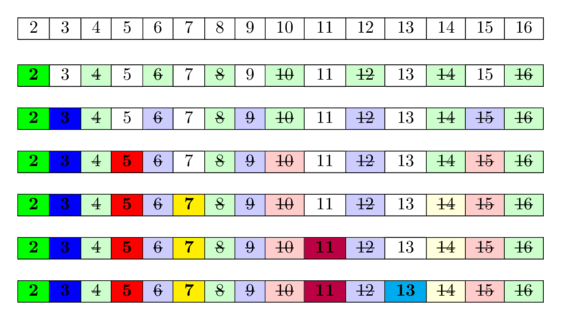
Tạo sàng các số từ $1$ tới $n$, đánh dấu $1$ không là số nguyên tố (hợp số).
Bắt đầu từ số nguyên tố đầu tiên là $2$, đánh dấu tất cả các bội số của $2$ là hợp số. ($4, 6, 8, …$)
TIếp tục duyệt đến số nguyên tố tiếp theo (không bị đánh dấu là hợp số), tìm được $3$. Tại $3$, đánh dấu tất cả bội số của $3$ là hợp số. ($6, 9, 12, …$)
Lặp lại tiếp sẽ được số nguyên tố tiếp theo là $5$ (do $4$ đã là bội của $2$). Tại $5$, đánh dấu các bội số của $5$ là hợp số. ($10,15, 20, …$).
Implementation
int n;
vector<char> is_prime(n+1, true);
is_prime[0] = is_prime[1] = false;
for (int i = 2; i <= n; i++) {
if (is_prime[i] && (long long)i * i <= n) {
for (int j = i * i; j <= n; j += i)
is_prime[j] = false;
}
}
Độ phức tạp: $O(n \log \log n)$
Không gian lưu trữ: $O(n)$
Cải tiến giải thuật
Điểm yếu của giải thuật trên là cần duyệt qua mọi số trong đoạn $1,n$, độ phức tạp và không gian lưu trữ sẽ lớn nếu cần xử lý với $n$ lớn (chẳng hạn với $n = 10^9$).
Duyệt đến $\sqrt{n}$
Để tìm mọi số nguyên tố trong đoạn $1,n$, ta chỉ cần duyệt đến $\sqrt{n}$.
int n;
vector<char> is_prime(n+1, true);
is_prime[0] = is_prime[1] = false;
for (int i = 2; i * i <= n; i++) {
if (is_prime[i]) {
for (int j = i * i; j <= n; j += i)
is_prime[j] = false;
}
}
Cải tiến này sẽ không giảm được độ phức tạp của giải thuật, tuy nhiên số thao tác sẽ giảm đáng kể.
Bỏ qua số chẵn
Bỏ qua việc đánh dấu bội số của $2$. Cải tiến này giảm được 1 nửa vùng nhờ và số thao tác.
Giảm không gian lưu trữ
Giải thuật này chỉ cần dùng $n$ bits trên memory, do đó ta có thể giảm từ $n$ bytes (khi dùng kiểu boolean) về $n$ bits.
Phương pháp này được gọi là bit-level compression, tuy nhiên việc đọc / ghi trên bit sẽ làm chậm đi thuật toán. Do đó chỉ nên áp dụng phương pháp này khi $n$ là quá lớn, không thể cấp được vùng nhớ tương ứng.
Segmented Sieve - Phân đoạn sàng
Trong cải tiến duyệt đến $\sqrt{n}$ ở trên, ta không cần duy trì vùng nhớ is_prime[1...n] mọi lúc. Để thực hiện sàng, ta chỉ cần giữ các số nguyên tố từ $1,\sqrt{n}$, tức chỉ cần dùng vùng nhớ prime[1... sqrt(n)] để biết được các số nguyên tố trong đoạn $1,\sqrt{n}$.
Tiếp theo để sàng được mọi số nguyên tố trong $1,n$, ta sẽ tách thành các đoạn / block để xét riêng biệt, dựa trên các số nguyên tố trên đoạn $1,\sqrt{n}$ đã sàng trước đó.
Gọi $s$ là size của block ta xét, ta sẽ có $\lceil {\frac n s} \rceil$ đoạn, với đoạn $k$ ($k = 0 … \lfloor {\frac n s} \rfloor$) chứa các số trong đoạn $[ks; ks + s - 1]$.
Lúc này ta có thể xử lý trên từng đoạn riên biệt mà không cần tốn kích thước sàng $O(n)$ như giải thuật trước.
Đây là ví dụ cho việc đếm số số nguyên tố $<= n$ sử dụng phương pháp này.
int count_primes(int n) {
const int S = 10000;
vector<int> primes;
int nsqrt = sqrt(n);
vector<char> is_prime(nsqrt + 1, true);
for (int i = 2; i <= nsqrt; i++) {
if (is_prime[i]) {
primes.push_back(i);
for (int j = i * i; j <= nsqrt; j += i)
is_prime[j] = false;
}
}
int result = 0;
vector<char> block(S);
for (int k = 0; k * S <= n; k++) {
fill(block.begin(), block.end(), true);
int start = k * S;
for (int p : primes) {
int start_idx = (start + p - 1) / p;
int j = max(start_idx, p) * p - start;
for (; j < S; j += p)
block[j] = false;
}
if (k == 0)
block[0] = block[1] = false;
for (int i = 0; i < S && start + i <= n; i++) {
if (block[i])
result++;
}
}
return result;
}
Độ phức tạp sẽ như giải thuật trước đó, tuy nhiên không gian lưu trữ sẽ giảm còn $O(\sqrt{n} + S)$. Kích thước $S$ cho đoạn được recommend là $10^4$ hoặc $10^5$.
Tìm mọi số nguyên tố trong đoạn $[L,R]$
Problem: tìm mọi số nguyên tố trong đoạn $[L,R]$ với $R - L + 1 \approx 10^7$ và $R$ có thể rất lớn, ví dụ $R = 10^12$.
Solution: sử dụng phân đoạn sàng như trên, tính sẵn các số nguyên tố trong đoạn $[1, \sqrt{R}]$.
vector<bool> segmentedSieve(long long L, long long R) {
// generate all primes up to sqrt(R)
long long lim = sqrt(R);
vector<bool> mark(lim + 1, false);
vector<long long> primes;
for (long long i = 2; i <= lim; ++i) {
if (!mark[i]) {
primes.emplace_back(i);
for (long long j = i * i; j <= lim; j += i)
mark[j] = true;
}
}
vector<bool> isPrime(R - L + 1, true);
for (long long i : primes)
for (long long j = max(i * i, (L + i - 1) / i * i); j <= R; j += i)
isPrime[j - L] = false;
if (L == 1)
isPrime[0] = false;
return isPrime;
}
Độ phức tạp: $O((R - L + 1) \log \log (R) + \sqrt R \log \log \sqrt R)$
Một solution khác không cần tạo trước các số nguyên tố trong đoạn $[1, \sqrt{R}]$.
vector<bool> segmentedSieveNoPreGen(long long L, long long R) {
vector<bool> isPrime(R - L + 1, true);
long long lim = sqrt(R);
for (long long i = 2; i <= lim; ++i)
for (long long j = max(i * i, (L + i - 1) / i * i); j <= R; j += i)
isPrime[j - L] = false;
if (L == 1)
isPrime[0] = false;
return isPrime;
}
Độ phức tạp: $O((R - L + 1) \log (R) + \sqrt R)$
Giải thuật theo thời gian tuyến tính
Chúng ta có thể thay đổi lại giải thuật sàng theo cách khác để được độ phức tạp theo thời gian tuyến tính. Chi tiết giải thuật được trình bày trong bài viết Sieve of Eratosthenes Having Linear Time Complexity. Tuy nhiên mỗi giải thuật đều sẽ có những yếu điểm riêng.
Practice Problems
- SPOJ - Printing Some Primes
- SPOJ - A Conjecture of Paul Erdos
- SPOJ - Primal Fear
- SPOJ - Primes Triangle (I)
- Codeforces - Almost Prime
- Codeforces - Sherlock And His Girlfriend
- SPOJ - Namit in Trouble
- SPOJ - Bazinga!
- Project Euler - Prime pair connection
- SPOJ - N-Factorful
- SPOJ - Binary Sequence of Prime Numbers
- UVA 11353 - A Different Kind of Sorting
- SPOJ - Prime Generator
- SPOJ - Printing some primes (hard)
- Codeforces - Nodbach Problem
- Codefoces - Colliders